Interesting. I’m just thinking aloud to understand this.
In this case, the models are looking at a few sequence of bytes in their context and are able to predict the next byte(s) with good accuracy, which allows efficient encoding. Most of our memories are associative, i.e. we associate them with some concept/name/idea. So, do you mean, our brain uses the concept to predict a token which gets decoded in the form of a memory?












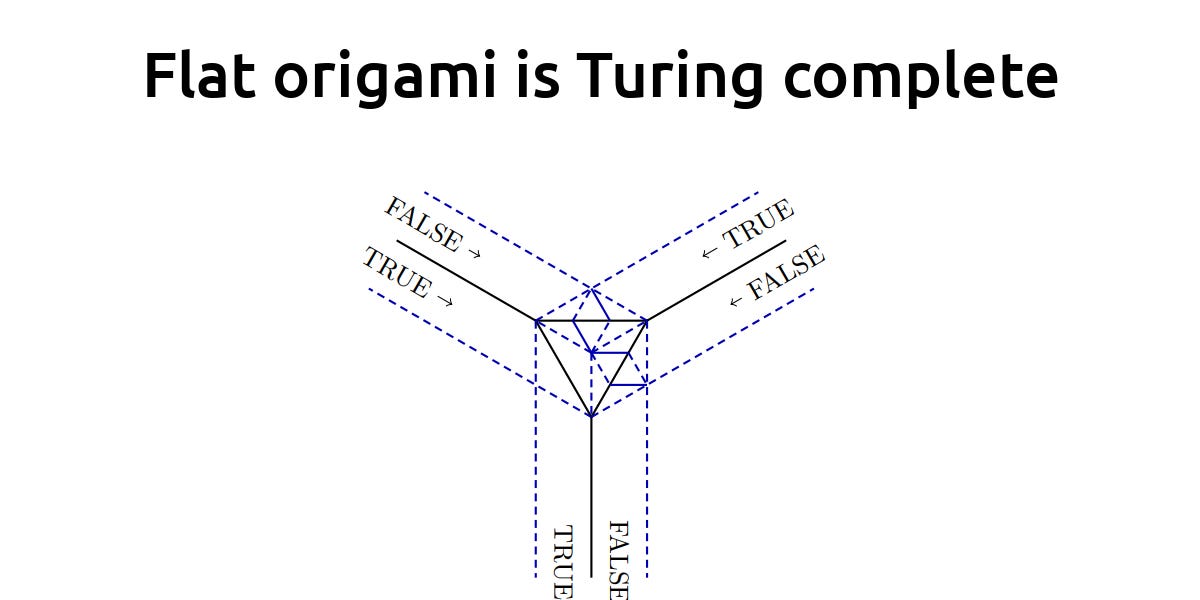


Yes, that makes much more sense.